Real MySQL을 읽다가 재미있는 내용을 발견해서 한 번 정리해봤습니다.
인덱스의 핵심은 값이 정렬되어 있다는 것입니다. 다중 컬럼 인덱스는 첫 번째 칼럼에 의존하여 두 번째 칼럼이 정렬되기 때문에 칼럼의 순서가 매우 중요합니다.
예를 들어
mysql> ALTER TABLE employees
ADD INDEX ix_gender_birthdate (gender, birth_date);위와 같은 다중 컬럼 인덱스가 생성되어 있다면 birth_date 칼럼은 gender에 의존적입니다. 따라서 birth_date만을 조건으로 조회를 할 경우 인덱스를 활용하지 못합니다.
그런데 MySQL 8.0부터 skip scan 최적화 기능이 도입되면서, birth_date 조건만으로 인덱스를 활용할 수 있게 되었습니다. 몇 가지 제약 사항이 있지만요.
Skip Scan Access Method
어떤 상황에서 이 최적화 기능을 활용할 수 있는지 알아보겠습니다.
MySQL 8.0 버전부터는 다중 칼럼 인덱스에서 옵티마이저가 특정 칼럼 인덱스를 건너 뛰어서 검색할 수 있도록하는 최적화 기능이 도입되었습니다. 그래서 이름이 skip scan이죠. 이를 통해 인덱스를 통한 검색의 용도가 더 넓어졌습니다.
예시를 통해 알아보겠습니다.
예시 테이블은 다음과 같습니다.
mysql> CREATE TABLE `employees` (
`emp_no` int NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`last_name` varchar(16) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`gender` enum('M','F') CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci STATS_PERSISTENT=0 |
다중 칼럼 인덱스를 사용할 경우, where 조건에서 첫 번째 칼럼을 사용하지 않으면 인덱스를 활용하지 못합니다.
mysql> ALTER TABLE employees
ADD INDEX ix_gender_birthdate (gender, birth_date);-- // 인덱스를 사용하지 못하는 쿼리
mysql> SELECT gender, birth_date FROM employees WHERE birth_date>='1965-02-01';
-- // 인덱스를 사용할 수 있는 쿼리
mysql > SELECT gender, birth_date FROM employees WHERE gender='M' AND birth_date>='1965-02-01';
각 쿼리의 실행계획은 다음과 같습니다. 우선 인덱스 스킵 스캔 기능을 비활성화한 후 실행 계획을 보겠습니다.
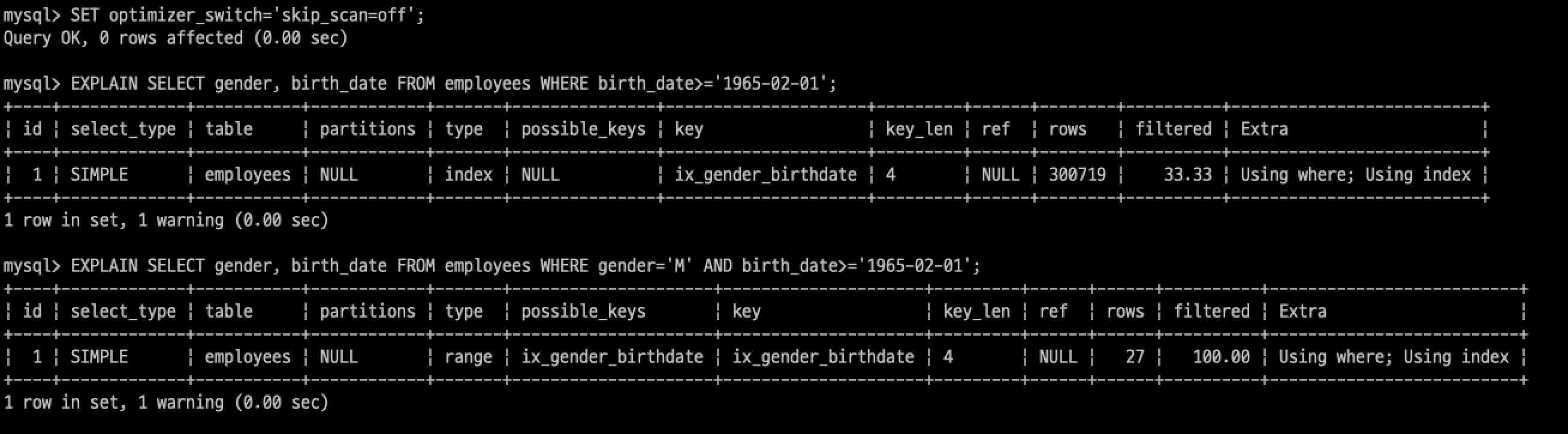
첫 번째 쿼리의 실행 계획을 보면 type이 index라고 되어 있습니다. 타입이 index라는 것은 인덱스를 처음부터 끝까지 다 읽었다는 것입니다. 즉 풀 인덱스 스캔이 일어난 것으로, 인덱스를 효율적으로 활용하지 못했음을 나타냅니다.
반면 두 번째 쿼리의 type은 range 입니다. 타입이 range라는 것은 인덱스에서 꼭 필요한 부분만 읽었다는 것입니다. 인덱스를 잘 활용했다고 평가할 수 있습니다.
이번에는 인덱스 스킵 스캔 기능을 활성화한 후 첫 번째 쿼리를 다시 실행해보겠습니다.

분명 같은 쿼리인데 이번에는 필요한 데이터만 읽은 것을 확인할 수 있습니다.
MySQL 옵티마이저는 우선 gender 칼럼에서 유니크한 값을 모두 조회한 후 주어진 쿼리에 gender 칼럼의 조건을 추가해 쿼리를 다시 실행하는 형태로 처리합니다.
제약 조건
그러나 인덱스 스킵 스캔은 아래의 조건을 만족해야 사용 가능하다는 단점이 있습니다.
- WHERE 조건절에 조건이 없는 인덱스의 선행 칼럼의 유니크한 값의 개수가 적어야함
- 쿼리가 인덱스에 존재하는 칼럼만으로 처리가 가능해야함.
첫 번째 제약 조건을 봅시다. gender의 경우 유니크한 값의 개수가 두 개입니다. 만약 유니크한 값의 개수가 많으면 MySQL 옵티마이저는 인덱스에서 스캔해야할 시작 지점을 검색하는 작업이 많이 필요해지기 때문에 쿼리의 성능이 떨어지게 됩니다.
유니크한 값이 어느 정도면 적은거고 어느 정도면 많은 건지는 상황에 따라 다르므로 실행 계획을 통해 확인할 수밖에 없을 것 같습니다. 명시적인 수치가 있나 싶어서 공식문서를 찾아봤는데, 이에 대한 언급은 없는 것으로 보입니다.
두 번째 제약 조건은 쿼리를 다음과 같이 바꿔봄으로써 확인할 수 있습니다.

type이 all이라는 것은 테이블 풀 스캔으로 실행 계획을 수립했다는 것입니다. gender와 birth_date만 조회하는 경우 인덱스에 존재하는 칼럼만 조회하면 되기 때문에 테이블을 스캔할 필요가 없습니다.
하지만 모든 컬럼을 조회하려면 테이블을 스캔해야 하기 때문에 테이블 풀 스캔으로 실행 계획이 수립되게 됩니다.
사용 가능한 상황의 특수성이 있긴 하지만 재미있는 내용이라 한 번 정리해봤습니다.
참고자료
Real MySQL
'Computer Science > 데이터베이스' 카테고리의 다른 글
| AUTO_INCREMENT는 ROLLBACK되지 않는다 (6) | 2022.04.27 |
|---|---|
| [DB] 트랜잭션 (Transaction) (0) | 2021.08.24 |


댓글